Real-World RL for Manipulation with HIL-SERL on LeRobot SO-101
Feb '26
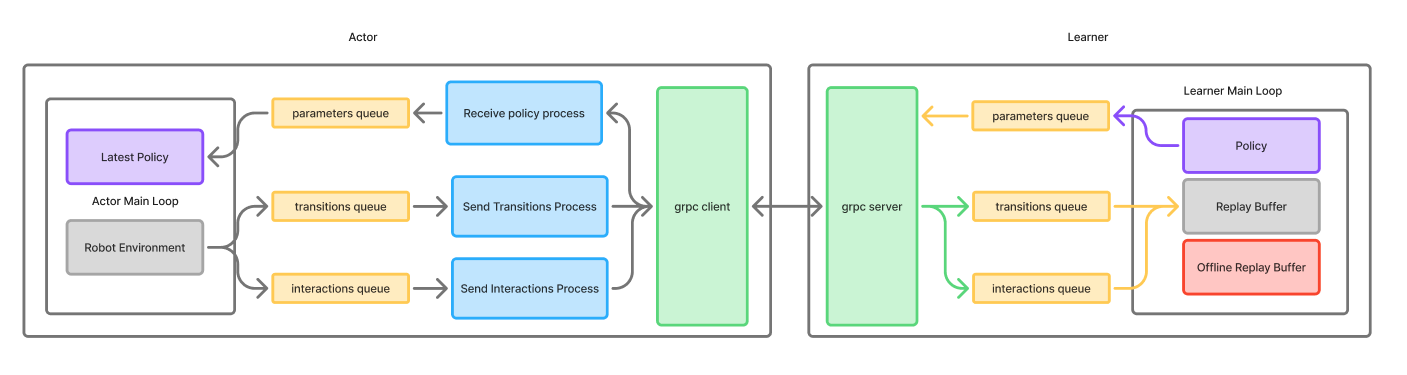
At the Seed Studio LeRobot hackathon in Mountain View, our team implemented HIL-SERL (Human-in-the-Loop Sample Efficient Reinforcement Learning) on the SO-101 robotic arm from Hugging Face’s LeRobot platform.
Motivation
We initially trained and deployed Vision-Language-Action (VLA) models for simple pick tasks but found they would overfit to exact object positions, requiring retraining whenever the workspace changed. This motivated us to explore reinforcement learning as a way to achieve more generalizable policies.
Approach
HIL-SERL combines two key ideas:
- Soft Actor-Critic (SAC): An off-policy maximum entropy RL algorithm that learns a stochastic policy
- RLPD (RL with Prior Data): Bootstrapping RL with expert demonstrations instead of training from scratch
The algorithm adds a human-in-the-loop correction procedure where an operator can intervene during training to help the policy experience reward more frequently.
Experiments
We ran a progression of experiments:
- Sim validation: Ported the HIL-SERL demo from MuJoCo Franka to SO-101 in Isaac Sim, achieving successful cube picking after ~1 hour of training
- Sim-to-real attempt: Trained for 16 hours in Isaac Sim and attempted direct transfer to hardware — this failed due to the large sim-to-real gap (visual differences, camera mounting, shadows)
- Fine-tuning from sim checkpoint: Resumed training on real hardware from the sim-trained checkpoint, achieving successful picks after ~4 hours of additional real-world training
- Training from scratch on hardware: With tighter workspace bounds, achieved a working pick policy in approximately 40 minutes of real-world training
Key Findings
- HIL-SERL can learn manipulation policies on hardware from scratch within 40 minutes with appropriately constrained workspace bounds
- The sim-to-real gap for vision-based policies remains significant — direct transfer failed, and it’s unclear if sim pretraining provided meaningful benefit
- RL data collection via interventions is less tedious than collecting full demonstration trajectories for imitation learning
- Strict workspace bounds around the task area dramatically improved sample efficiency by reducing irrelevant exploration
Team
Bruce Kim, Siddharth Saha, Cyan Ding, Indraneel Patil